Introduction to Pattern Matching
| Version | Version Information | Date |
| Initial version | Nadya Morozova, Nikolay Kuznetsov: document created. | December 16, 2005 |
Copyright 2005 The Apache Software Foundation or its licensors, as applicable.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
This document describes the java.util.regex package delivered as part of
the Harmony classlibrary project. This document provides an overview
of the overall architecture with focus on the aspects improving performance.
The target audience for the document includes a wide community of engineers interested in using regular expression package and in further work with the product to contribute to its development. The document assumes that readers are familiar with Regular expressions [1, 2, 3], finite automata theory [4], basic compiler techniques [4] and the Java* programming language [5].
This document uses the unified conventions for the Harmony documentation kit.
To analyze text in search of sequences matching preset patterns, you can choose from a variety of techniques, such as the wide-spread regular expressions (RE) [1], exact string matching, for example, the Boyer-Moore algorithm (BM) [6], and others. However, the RE engine is rather complex, and significantly impacts performance, whereas the exact string matching techniques have a limited application.
For example, the regular expression .*world is used to find the
last instance of world in a sentence. The BM string searching algorithm is more
appropriate for solving the task than the RE technique, and is more effective
from the performance perspective. To optimize using pattern matching techniques
with different tasks, Harmony provides a unified interface that applies to any part
of a regular expression, including the whole expression.
In terms of the Finite Automata theory, which is the basis of regular expression
processing, a part of regular expression is a node. The Harmony regex framework
treats every distinctive part of a regular expression and the whole expression
as a node. Each node implements the unified interface adjusted for a specific
technique. For instance, for the regular expression in the example, the Harmony
framework includes a special class SequenceSet, which has a unified interface
called AbstractSet, and implements the Boyer-Moore algorithm in
searching for a word.
The key feature of the Harmony regex framework the single super interface, AbstractSet,
shared by all types of nodes. Individual nodes are independent, so that every
node of the automaton incorporates its own find-match algorithm optimized for
a specific type of nodes. You can use methods implemented in the AbstractSet
interface subclasses or override these methods to use your own more efficient
algorithm.
The AbstractSet interface has the following key characteristics:
NOTE:
Because new features and optimizations are implemented independently, expansion of the framework has no negative impact on the overall performance.
The AbstractSet interface defines the matching and finding methods,
and the service methods supporting them, as follows.
Service Methods
accept()
method, see Example 1.Matching and Finding Methods
matches() method does the following when working with terms (see Class
Hierarchy):
accept() method and proceeds if the method returns
a positive value. accept()
method.TRUE in case of a successful match. accept()
method returns a positive value. If no matches are found, the method terminates
and returns a negative value.matches() method.find() method but.*world
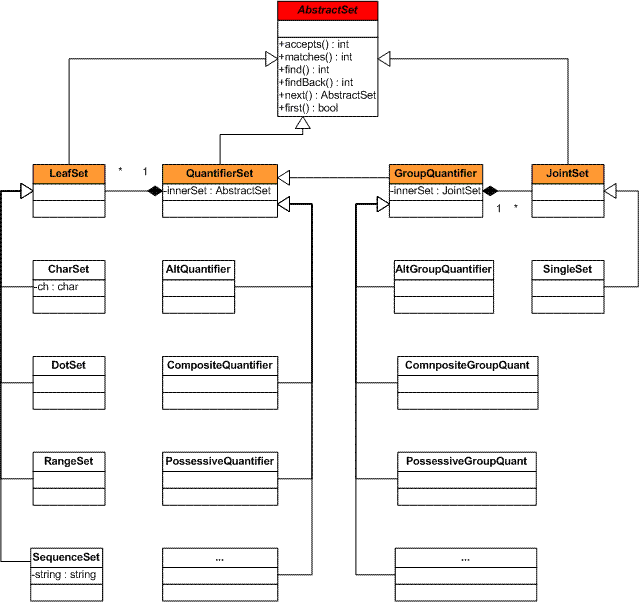
pattern. Figure 1 shows the class hierarchy based on the AbstractSet
interface. As mentioned in its description,
the whole hierarchy is based on this interface. The other classes of the framework
are divided into the following categories:
LeafSet in the figure): nodes representing
ordinal symbols, substrings, ranges, character classes, and other basic units
of regular expressions.
QuantifierSet in the figure): set of nodes responsible
for quantification of terms. Terms are simple and usually represent only one
symbol. Therefore, terms are quantified without recursion, and backtracks are
processed on the basis of the underlying pattern length.
JointSet in the figure): sets derived from parenthetic constructions.
These nodes represent alternations of other sets.
GroupQuantifier in the figure): special
quantifiers over Groups. Because the length of a groups can vary, backtracks
require recursion.
Figure 1 displays only the basics of the regex framework. This framework also includes other nodes responsible for different optimizations. For more details, see the comments inlined in code.
In the current implementation, most optimizations are based on the node representation to improve efficiency of the framework. It is noteworthy that an optimal finite automaton is built during compile time, so that the constructed automaton does not spend additional time on decision-making overhead during match time. The regex framework optimizations improve different aspects, such as:
find()
and findBack() of certain nodes use exact pattern matching algorithms,
specifically, the Boyer-Moore fast string search algorithm.
.*) covers the rest
of the string and can therefore run findBack() from the end of
the string. If the findBack() method of the following node implements
a special algorithm, the pattern matching speed for this chain increases,
otherwise the operation runs at the same speed.
This part on the document illustrates usage of the Harmony regex framework.
This example illustrates using the CharSet class, which includes all nodes accepting characters to create a new type of tokens. For that, the class uses the LeafSet class, which is the basic class for tokens. This example shows that the only method you need to override in order to present a new type of tokens is the accept() method.
class CharSet extends LeafSet {
...
public int accept(int strIndex, CharSequence testString) {
// checks that the current symbol of the input string is the one this
// instance represents and returns 1 (the number of
// accepted symbols) or -1 if accept fails:
return (this.ch == testString.charAt(strIndex)) ? 1 : -1;
}
...
}
The following example demonstrates independent implementation of the find() method for SequenceSet.
Note:
This changes the find procedure for nodes representing character sequences and at the same time does not affect the find-match algorithms of other types of nodes.
class SequenceSet extends LeafSet {
...
protected int indexOf(CharSequence str, int from) {
// Boyer-Moore algorithm
...
}
public int find(int strIndex, CharSequence testString,
MatchResultImpl matchResult) {
...
while (strIndex <= strLength) {
// call the fast search method instead of default implementation
strIndex = indexOf(testStr, strIndex);
if (strIndex < 0) {
return -1;
}
if (next.matches(strIndex + charCount, testString, matchResult) >= 0) {
return strIndex;
}
strIndex++;
}
return -1;
}
...
}
This example illustrates how to turn the match procedure of the .*
patterns into the find procedure, which is potentially faster.
class DotQuantifierSet extends LeafQuantifierSet {
...
public int matches(int stringIndex, CharSequence testString,
MatchResultImpl matchResult) {
...
// find line terminator, since .* represented by this node accepts all characters
// except line terminators
int startSearch = findLineTerminator(stringIndex, strLength, testString);
...
// run findBack method of the next node, because the previous
// part of the string is accepted by .* and no matter where
// the next part of pattern is found, the procedure works OK.
return next.findBack(stringIndex, startSearch, testString, matchResult);
}
}
[1] Jeffrey E. F. Friedl., Mastering regular expressions, 2nd Edition., July 2002, O'Reilly, ISBN 0-596-00289-0
[2] McNaughton, R. and Yamada, H. Regular Expressions and State Graphs for Automata, IRA Trans. on Electronic Computers, Vol. EC-9, No. 1, Mar. 1960, pp 39-47.
[3] Thompson, K., Regular Expression search Algorithm, Communication ACM 11:6 (1968), pp. 419-422.
[4] Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman, Compilers, Principles Techniques and Tools, Addison-Wesley Publishing Company, Inc., 1985, ISBN 0-201-10088-6
[5] Java Technology site, http://java.sun.com
[6] R. Boyer and S. Moore. A fast string searching algorithm. C. ACM, 20:762-772, 1977.
[7] D.E. Knuth, .I. Morris, and V. Pratt. Fast pattern matching in strings. SIAM J on Computing, 6:323-350, 1977.
* Other brands and names are the property of their respective owners.